Merhabalar ben Dilara Akbunar. Başkent Üniversitesi Biyomedikal Mühendisliği son sınıf öğrencisi olarak, alanımda da son zamanlarla sıklıkla duyduğum bir konu olan biyoinformatikte makine öğrenmesi ve tekniklerinden bahsetmek istiyorum. Bu alanda benim gibi araştırmalara başlamak isteyenler için referanslarımı incelemenizi içtenlikle öneririm. Öncelikle adını sıkça duyduğumuz biyoinformatik kavramından başlayacağım.Aslında tek bir tanımı vardır diyemeyiz. Birden fazla tanım yapılmıştır.
“Amerikan Ulusal Biyoteknoloji Bilgi Merkezi NCBI’nın (National Center for Biotechnology Information) internet sayfasında biyoinformatik; biyoloji, bilgisayar bilimi ve bilgi teknolojilerinin birleşiminden oluşan bir disiplin olarak tanımlanmıştır”, “Biyoinformatik multidisipliner çalışmaktadır. Bilgisayar bilimleri, biyoistatistik sayesinde biyokimya ve biyoloji, genetik, tıbbi biyoloji hatta fizyoloji gibi biyomedikal bilimlerinin bir bütününün sonucu olarak karşımıza çıkmaktadır. Bir diğer benzer tanımlamayı Luscombe ve arkadaşları da kullanmıştır. Şimdi kavram olarak bir fikre sahip olduğunuza göre biyoinformatik teriminin tarihçesine kısaca değinmek isterim.
Pauling ve Corey’in 1951 yılında proteinlerin sekonder yapılarının doğru bir şekilde tahmin edilmesi ile ilgili geliştirdikleri yaklaşım biyoinformatik için başlangıç kabul edilmekle birlikte asıl olarak başlangıç 1966 yılında bilgisayarla moleküler grafiklerin çizimine ait ilk makalenin “Scientific American” isimli dergide yayınlanmasıyla olmuştur. Ayrıca biyoinformatik alanında önemli bir yere sahip olan İnsan Genom Projesi ise 1990’da başlamıştır. Projenin amaçları ise DNA ve protein bilgilerinin yer aldığı veri tabanları, insan DNA’sındaki 20.000-25.000 genin tanımlanması, hastalıkların erkenden tedavi edilmesinin sağlanması şeklinde sıralayabiliriz.

Biyoinformatiğin Temel Hedefleri
Biyoinformatik biliminin üç ana hadefi vardır.İlk hedefi ilgili kişilerin biyolojik verilere ulaşabilmesini ve yenilerinin de yüklenebileceği bir şekilde düzenlenmesidir. Buna veri tabanı oluşturmak diyoruz. Analiz edilmeyen veri tabanındaki bilgiler kullanışsız bilgi olarak kabul edilmektedir.Analiz kısımlarında kullanılan teknikler ve araçları geliştirmek de biyoinformatiğin ikinci hedefi olarak karşımıza çıkar. Bu konuyu basite alamayız. Örnek verecek olursak aminoasit dizisinin belirli bir proteiniyle dizi özellikleri belirli olan bir diğer proteinin karşılaştırma durumunda yazılım araştırması yeterli gelmeyecek olup bu moleküllerin biyolojik içeriklerinin de incelenmesi gerekebilir. Bunun için kullanılan BLAST nükleotid/protein dizisi karşılaştırması yapan bir algoritma olup bunun gibi yazılım kaynaklarının geliştirilmesi hususunda da biyoloji bilgisi gerektiği kadar bilişim alanlarında da uzmanlık şarttır. Üçüncü hedef ise elde edilen bilgileri biyolojik açıdan anlamlı bir şekilde analiz etmektir.
Günümüze Gelecek Olursak…
Son zamanlarda hepimizin sıklıkla duyduğu kavramlar arasında büyük veri (big data) yer almaktadır. İnternet kullanan her bireyin büyümesine ve gelişmesine katkı sağladığı büyük veri; gözlemlerden, araştırmalardan, arama motorlarından, bloglardan, forumlardan, sosyal medyadan ve diğer birçok kaynaktan elde edilen verilerin anlamlı ve işlenebilir hale getirilmiş biçimine denir.
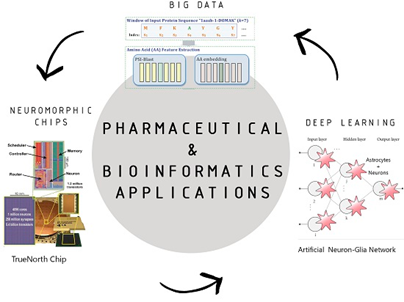
Farklı bilim dallarının yer aldığı biyoinformatikte ise genom dizileme, omiks çalışmalar, mikrodizi gen ifade, ilaç molekül çalışmaları ile ilişkisinin bulunması,biyolojik verilerin artması sorunlarını da beraberinde getirmektedir. Biyoinformatikte en büyük problemlerden olan ikinci problem bahsedilen tüm bu verilerin biyolojik bilgilere dönüştürülme hususunda kullanılan yöntem ve araçların iyi bilinmesi gerekir. Bu yöntem araçlarının uygulanmasında bilgisayar bilimleri ve biyoistatistik gibi disiplinlerin entegrasyonundan ortaya çıkan teknikler uygulanmaktadır. Size birkaç biyoinformatik uygulamasından bahsedeceğim. Bu uygulamalar yalnızca var olan uygulamaların çok az bir kısmını oluşturduğunu da bilmenizi isterim.
Homologlar
Biyoinformatik farklı biyomoleküller arasındaki benzerlikleri aramaktadır. Bu konuda sistematik olarak veri organizasyonu sağlamadan protein türdeşlerini tanımlamada kullanılan pratik uygulamalar mevcuttur. Bunlardan biri proteinler arası gerçekleşen bilgi aktarımıdır. Örnek verecek olursak elimizde karakteristiği tam olarak belirlenmemiş protein için daha iyi anlaşılabilmesi adına homologları bulunarak elde edilen bilgiler değerlendirilir ve veri yetersiz kaldığında, bu yapılan çalışmalar düşük seviyeli organizmalardan insan gibi üst düzey organizmalardaki homologlarda bile uygulanır.
Rasyonel İlaçların Geliştirilmesi
Bir diğer uygulama örneği olan rasyonel ilaçların geliştirilmesi biyoinformatiğin tıbbi çalışmalarıyla mümkün olmuştur. Translasyon yazılımı kullanarak nükleotid sekansı verilen proteinin muhtemel amino asit sekansı belirlenebilmektedir. Burada kullanılan sekans arama teknikleri organizmada homologları bulmada da tercih edilebilmektedir. Bu deneysel çalışmalar başka organizmalarda insana ait protein yapılarını modellemeye olanak tanır. Öte yandan bağlantı algoritmaları sayesinde gerçekte protein üzerindeki etkinliği ölçülerek biyokimyasal tahlillere olanak tanıyabilir ve bu şekilde de protein yapısına bağlanan moleküller tasarlanmaktadır. Bahsedilen Gen ekspresyon analizleri hastalık teşhisi ve hedef ilaç tasarımında yararlanılmaktadır.
Veri Tabanları
Biyoinformatiğin en önemli işlevlerinden birisi de veri kaynaklarından elde edilen bilgilerin birleştirilmesidir.Bu durum avantajlı olmasına rağmen dizinlerdeki ve dosya biçimlerindeki farklılıklar sebebiyle bilgi kaynaklarını etkili kullanırken sıkıntı yaratabilmektedir. Temel düzeyde, bu sorunun çözümüne yönelik olarak birçok veri kaynağına erişim sağlanabilecek şekilde veri kaynaklarını birleştirme çabası vardır. Bu konu için 2 erişim sistemi mevcuttur. Biri düz dosya veri tabanlarının birbirlerine endekslenmesine, protein yapısına, dizisine olanak sağlayan, Dizi Erişim Sistemidir (Sliding Rail System). Diğeri de DNA’ya, protein dizilerine, genom harita verilerine, 3D makromoleküler yapılara ve PubMed bibliyografik veri tabanına benzer yollarla erişim sağlayan Entrez sistemidir. Yukarıda da bahsettiğim gibi biyoinformatik adı altında yapılan uygulamalar çok önemli hizmetler vermektedir. Ayrıca bahsettiklerimden daha fazla çalışma alanları mevcuttur.
Büyük Veri Doğru Kullanılırsa
Büyük verinin dezavantajları olduğu gibi avantajları da mevcuttur. Bahsedilen kanser ve nirodejeneratif hastalıklar gibi ciddi hastalıkların erken uyarı sistemleri, ilaçların keşfi, salgınların tahmini konularında bilginin artmasını sağlar. Böylece bu bilgilerimizi artıracak yeni teşhis araçlarının ortaya çıkmasına öncülük etmektedir.
Artık biyoinformatik üzerine yüzeysel ama geniş çaplı bir fikriniz olduğuna göre biyoinformatiğin makine öğrenmesiyle yollarının hangi noktalarda kesiştiğine değinmek isterim.
Makine Öğrenmesi ve MÖ Algoritmaları
Hesaplama konusundaki zorluğun artması ve büyük verinin hacimsel potansiyeli sonucunda derin öğrenme son teknolojiyle birlikte başarılı makine öğrenme (machine learning) algoritmaları haline gelmiştir. Makine öğrenim teknikleri, biyolojik verilerden bilgiyi çıkarma konusunda hesaplama yöntemleri olarak yardımcı olmaktadır. Aynı zamanda bu teknikler model oluşturmaya da yardımcı olduğu için biyoinformatik alanında oldukça önemlidir. ML modeller biyoinformatikte biyolojik verileri öğrenir ve bunlara ilişkin tahminlerde bulunur.Kafanızda daha çok canlanması adına “Machine Learning in Bioinformatics,Jyotsna T Wassan, Haiying Wang, and Huiru Zheng, Ulster University, County Antrim, Northern Ireland, United Kingdom,2018” adlı makelede geçen örnekten bahsetmek isterim.
F(x)=y olarak bildiğimiz fonksiyon gösteriminden yola çıkarsak
- Eğer X biyolojik veri olarak hareket ederse, Y, X’ten türetilmiş biyolojik bilgidir.
- Diğer bir durumda X biyolojik veri olarak hareket ettiği takdirde, F, X’e göre fonksiyonel yaklaşım olmaktadır. Y ise yeni türetilmiş biyolojik bilgidir.
Artık size biyolojik tahminler için temsili makine öğrenimi algoritmalarından bahsedebilirim.
Sınıflandırma
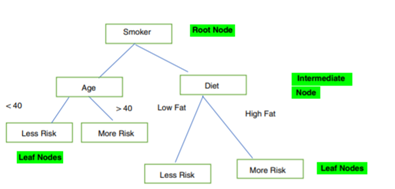
Sınıflandırma problemini baz aldığımızda veri ögeleri kümesinin sınıflar olarak bölünmesi gerekir. Bir öge kümesi ögelerin bazı özelliklerine göre bir dizi sınıflandırma kuralına göre bir sınıf atanmaktadır. Bunlardan en bilinen karar ağaçları biyolojik verilerdeki özellikler arası ilişkinin hiyerarşik temsilidir. Bir dizi özelliğin sınıflandırılmasına dayanan yöntemde aşağıdaki şekli de baz alırsak yaprak, düğümler kategori/sınıflara göre sınıflandırılan örnekleri temsil eder.
Bir diğer sınıflandırma da Rastgele Orman ve XGBoost olarak adlandırılır. Rastgele bir gözlem örneği alınır ve bir karar ağacı modeli oluşturmak için ilk ögeler seçilir. Süreç birçok kez tekrarlanır. Son olarak da farklı karar ağaçlarından türetilen her bir öngörünün fonksiyonun tahmin gerçekleştirilir. Rastgele Ormanı daha hızlı yapmak için XGBoost hesaplamadan yararlanılır. XGBoost, karar ağacı tabanlı bir topluluk Makine Öğrenimi algoritmasıdır. En az bilgi işlem miktarıyla daha büyük verilere ölçeklenmesine olanak tanır.
Destek Vektör Makineleri
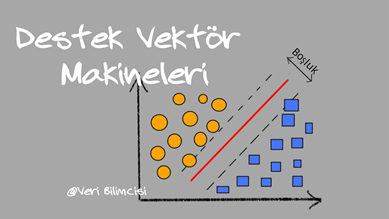
Bu sistemde amaç şekilde de görüldüğü üzere verileri ayıran bir çizgi sunmaktır. Hat bir sınıflandırma görevi görmektedir. Örneğin iki örnek özelliği varsa (yaş ve sigara içme durumu olarak düşünebiliriz) bir birey olarak iki değişken, iki boyutlu bir boşlukta çizilir. Her noktanın dolayısıyla iki koordinatı vardır.
Yapay Sinir Ağları
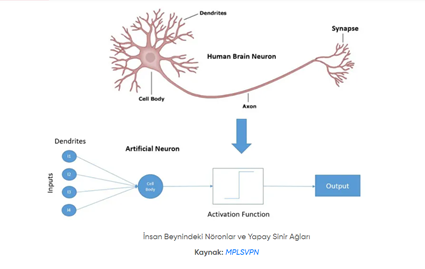
Makine öğrenmesi Yapay Sinir Ağları kavramını da beraberinde getirmiştir. Bu kavram insan beynin özelliği olan öğrenme mekanizmasının basit düzeyde adeta simüle edilmiş hali olarak karşımıza çıkmaktadır. Yapay sinir ağları, insan beyni gibi girdiler, işlemler, çıktılardan oluşmaktadır. İnsan beyninde nöronlardaki dentritler diğer nöronlardan bilgiyi alır. Daha sonrasında bilginin işlenmesinde aracı olur. Bilgiler hücre gövdesinde işlenir ve aksonlar da bu bilgileri sinapslara iletir. Sinapslar da diğer nöronlar ile haberleşmek için adeta bir çıktı görevi görmektedir .Yapay sinir ağlarında ise temel işlem birimleri(nöronlar veya düğümler) katmanlar halinde ve genellikle iki ardışık kavramın bağlanması şeklinde organize edilmektedir. Nöral ağ yapısında bir ünite önceki katmana ait birkaç ünite hakkında bilgi alır. Algıron adı verilen en basit nöral ağ ,eşik etkinleştirme işlevi kullanarak 2 sınıfı doğrusal bir şekilde ayıran tek nöron sınıflandırıcıdır. İleri bir yapı olarak da algıları birbirine bağlayan bir nöron tasarımı oluşturulabilir. Buna da çok katmanlı algıron adı verilmektedir.
Kümeleme
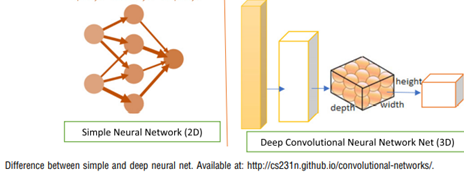
Kümeleme makine öğrenmesi algoritmalarından bir diğeri olarak karşımıza çıkmaktadır. Kümele içsel gruplandırmaya dayanmaktadır. Grup üyelerini birbirine benziyor ve diğer gruplara ait öğelere benzemiyorlar olarak düzenleyen bir tekniktir. Kümeleme yöntemleri de kendi içerisinde Bölünme yöntemleri, Hiyerarşik yöntemler, Association Rule Madenciliği, Derin Evrişimli Ağlar olarak ayrılmaktadır. Aşağıdaki şekilde de görüldüğü üzere derin evrişimli ağlar 2 boyutlu nöral ağların aksine genişlik yükseklik ve derinlik olarak çıkmaktadır.
Bu ağların tanımını açmamdaki en büyük neden de ilaç keşfinde bu ağların başarıyla kullanılmasıdır. Moleküler ve biyolojik proteinler arasındaki etkileşimin tahmin edilmesinden potansiyel tedaviler elde edilmektedir. Makine öğrenimi için kullanılan algoritmalar hakkında fikir sahibi olduğunuza göre kullanılan araçlar nelerdir sorusuna yanıt vermek için aşağıda incelediğim birkaç araçtan bahsetmek isterim. Bahsedeceğim araçlar veri hazırlığı ve öngörülü modellemeye yardımcı olmaktadır.
ML Yazılımları
ML yazılımları biyolojik etki alanındaki sorunları çözen veri biliminin ayrılmaz bir parçası haline gelmiştir. Bu dört araçtan ilki RapidMiner ilk olarak 2001 yılında Ralf Klinkenberg tarafından java programlama dilinde geliştirilmiştir. Şablon tabanlı bir blok diagram yaklaşımına dayanan açık kaynaklı bir Grafik Kullanıcı Arabirimi görevi görür.Ayrıca 2016 yılında yürütülen yıllık yazılım anketi ile en popüler veri analizi yazılımı olduğu ilan edilmiştir. KDnuggets (Jupp 2011). Biyoinformatik iş akışlarına ML araçlarının toplu bir şekilde uygulanmasını sağlamıştır.
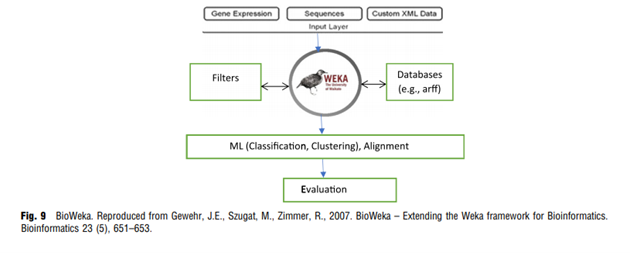
İkinci yazılım örneği ise Bioweka‘dır. Bilgi analizi için Weka ortamı, iyi görselleştirmeye sahip unsur seçimi gibi veri ön işleme yöntemleriyle çeşitli sınıflandırma, regresyon, kümeleme algoritmalarını destekler. Şekilde de gösterildiği gibi BioWeka projesinin bir parçası olarak Weka ‘ya biyoinformatik yöntemlerini tanıtmıştır.
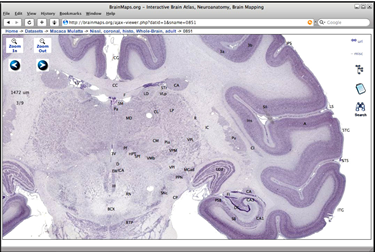
Bir diğer örnek vereceğim araç, Biyomedikal Mühendisi olarak da kullandığım MATLAB biyolojik sistemlerin modellenmesi ve simülasyonu konusunda entegre bir ortam sağlar. Mikrodiziler üzerinden veri analizi gerçekleştirmek için MATLAB ve ilgili araç kutuları kullanılmaktadır. Biyomkimyasal bileşikleri ölçmek, tıbbi görüntü işleme, biyolojik ve biyoistatistiksel simülasyon yapmak için çok fazla tercih edilen bir araçtır. Simbioloji kütüphanesi sayesinde sistemler için bir grafik ve modelleme aracı sağlamaktadır. MATLAB’ ın biyolojik görselleştirmede yararlı olduğu kanıtlanmıştır. Örneğin, BrainMaps şekilde de görüldüğü üzere yüksek çözünürlüklü beyin görüntü verilerini analiz etmekte kullanılır. MATLAB’a alternatif olarak da R, Python gibi açık kaynaklı programlama dilleri kullanılmaktadır.
Son olarak bahsedeceğim R-Project biyolojik verilerde en güçlü istatistiksel araç olarak ortaya çıkmasıyla birlikte analiz ve görselleştirme için çeşitli paketler sunmaktadır. Yaygın olarak üretilen moleküler genomik veriler ile bunların işlenmesi için ihtiyaç duyulan açık kaynak kodlu bir araçtır. R programlama dili kısaca veri analizi, verileri temizlemek, görselleştirmek, analiz etmek, istatistiksel hesaplama alanlarında kullanılan bir programlama dilidir.
Özetle ML tekniklerinin uygulanması gen montajı, veri analizi, moleküler yapısal modelleme dahil olmak üzere birçok biyolojik patternleri ve tahminleri bulmaya odaklamaya yardımcı olmaktadır. Şimdi ve gelecekte de biyolojik veriler katlanarak büyüdükçe, gelecek biyoinformatik için ölçeklenebilir Ml algoritmalarını geliştirmekte yatmaktadır. Aşağıda da belirttiğim, yazımda da kullandığım ve ek olarak eklediğim kaynaklara bakmanızı tavsiye ederim. Bu alanda yapılan çalışmaları en azından araştırmaya başlamak bile bir adım olduğu için sizlere bu yazımı ulaştırmak istedim.

Dilara AKBUNAR
PharmaIno Science IT Intern
Başkent Üniversitesi Biyomedikal Mühendisliği
REFERANSLAR
- Machine Learning in Bioinformatics /Jyotsna T Wassan, Haiying Wang, and Huiru Zheng, Ulster University, County Antrim, Northern Ireland, United Kingdom,2018
- Disiplinler Arası Bir Bilim Dalı: Biyoinformatik/ A.Ceren Akın, Büşra Bürçe, Burak Çevirici, Bengisu Şahin, Eda Şahin, Yağmur Şahin/ Danışman: Doç. Dr. A. Canan Yazıcı
- Biyoinformatik ve biyoistatistik/ Erdem Karabulut, Ergun Karaağoğlu/Doç. Dr., Hacettepe Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı, Ankara /Prof. Dr.Hacettepe Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı, Ankara,2010
- Machine Learning in Bioinformatics
- Inhibition of SARS-CoV-2 main protease: a repurposing study that targets the dimer interface of the protein Hanife Pekel, Metehan Ilter & Ozge Sensoy To cite this article: Hanife Pekel, Metehan Ilter & Ozge Sensoy,2021
- www.evrimagaci.org/ Dilara Karabekmez, Çağrı Mert Bakırcı 6 Ocak 2021
- www.medium.com.tr/ Rahime Yeşil 8 Nisan 2020
- GENETİK ANALİZ İÇİN BİYOİNFORMATİK YÖNTEMLER/DOÇ.DR.MUHAMMET ŞAKİROĞLU/PALME YAYINEVİ,2020

